| Start the Lab | Math Alive | Welcome Page |
You can answer by filling in the blank spaces. If there is not enough space attach other sheets.
In this problem set we will illustrate two compression schemes. The first one is (a very simple version of) the Lempel-Ziv algorithm. This is a scheme that can be used to compress any type of file (text or other), and it can be implemented in many ways, and using many different alphabets. We shall work with normal text and learn about a naive LZ algorithm. We start with some exercises to understand how it works.
Problem 1. Lempel-Ziv Parsing.
The first step in the algorithm is the parsing process.
The parsing is explained on the Lempel-Ziv
parsing webpage, with a worked example, followed
by an example for you to work through where you
get an explanation if you have any problems.
Can you parse the following sentence?
can_you_can_a_can_as_a_canner_can_can_a_can?
We have replaced the spaces in the sentence with the "_" character to make it easier to keep track of the spaces and we copied the sentence below, in the Answer so that all you have to do is add the parsing commas.
Answer:
can_you_can_a_can_as_a_canner_can_can_a_can?
Problem 2. Lempel-Ziv Compression.
The next step in the Lempel-Ziv algorithm is the coding of individual strings which is explained on the Lempel-Ziv coding webpage.
The example for which parsing is worked out is:
If_one_doctor_doctors_another_doctor, _does_the_doctor_who_doctors_the_doctor_ doctor_the_doctor_the_way_the_doctor_he_is_doctoring_doctors? _Or_does_he_doctor_the_doctor_the_way_the_doctor_who_doctors_doctors?which parses as follows:
,I,f,_,o,n,e,_d,oc,t,or,_do,c,to,r,s,_a,no,th,er,_doc,tor,,, _doe,s_,the,_doct,or_,w,h,o_, d,oct,ors,_t,he,_docto,r_, do,ct,or_t,he_,doc,tor_,the_,wa,y,_th,e_,doct,or_h,e_i,s_d, octo,ri,ng,_doctor,s?, _O,r_d,oe,s_h,e_d,octor,_the,_doctor_,the_w,a,y_, the_d,octor_, wh,o_d,octors,_doctors,?
To LZ compress this sentence, we number these strings. The first string, before the first comma, is the empty string (we always start with this), and we give it label 0. We now number all the following strings consecutively. The following table shows the compression process for the first few strings. This last column is the one that is important for us as it contains the LZ compressed sentence. On the webpage, you can practice completing the compression process for this example sentence.
| String | Position Number of this string | Prefix | Position Number of Prefix | Coded String |
|---|---|---|---|---|
| I | 1 | empty | 0 | 0I |
| f | 2 | empty | 0 | 0f |
| _ | 3 | empty | 0 | 0_ |
| o | 4 | empty | 0 | 0o |
| n | 5 | empty | 0 | 0n |
| e | 6 | empty | 0 | 0e |
| _d | 7 | _ | 3 | 3d |
| oc | 8 | o | 4 | 4c |
Complete now the following compression table for the sentence you parsed in Problem 1 (we have filled in the first two rows to get you started).
Answer:
| String | Position Number of this string | Prefix | Position Number of Prefix | Coded String |
|---|---|---|---|---|
| c | 1 | empty | 0 | 0c |
| a | 2 | empty | 0 | 0a |
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 | ||||
| 9 | ||||
| 10 | ||||
| 11 | ||||
| 12 | ||||
| 13 | ||||
| 14 | ||||
| 15 | ||||
| 16 | ||||
| 17 | ||||
| 18 | ||||
| 19 | ||||
| 20 | ||||
| 21 | ||||
| 22 | ||||
| 23 |
Write here the entire compressed sequence.
Answer:
Problem 3. Lempel-Ziv Deompression.
Now that we have performed the LZ compression, let's try LZ decompression. To LZ decompress a sentence, we simply reverse the compression process. Decompress the following sentence by filling in the table below (we have filled in the first eight rows to get you started).
0J0o0h0n0,0_0w3i0l0e6J0i0m6h0a0d14a16_0"3a16,19_20d17d6"23_ 23.22"0H15d24"24_26a6b10t0t10r6e0f39e0c36_2n6t3e44e15c45r0.
Answer:
| Coded String | Position Number of this string | Position Number of Prefix | Prefix String | Suffix String | Decoded String |
|---|---|---|---|---|---|
| 0J | 1 | 0 | empty | J | J |
| 0o | 2 | 0 | empty | o | o |
| 0h | 3 | 0 | empty | h | h |
| 0n | 4 | 0 | empty | n | n |
| 0, | 5 | 0 | empty | , | , |
| 0_ | 6 | 0 | empty | _ | _ |
| 0w | 7 | 0 | empty | w | w |
| 3i | 8 | 3 | h | i | hi |
| 9 | |||||
| 10 | |||||
| 11 | |||||
| 12 | |||||
| 13 | |||||
| 14 | |||||
| 15 | |||||
| 16 | |||||
| 17 | |||||
| 18 | |||||
| 19 | |||||
| 20 | |||||
| 21 | |||||
| 22 | |||||
| 23 | |||||
| 24 | |||||
| 25 | |||||
| 26 | |||||
| 27 | |||||
| 28 | |||||
| 29 | |||||
| 30 | |||||
| 31 | |||||
| 32 | |||||
| 33 | |||||
| 34 | |||||
| 35 | |||||
| 36 | |||||
| 37 | |||||
| 38 | |||||
| 39 | |||||
| 40 | |||||
| 41 | |||||
| 42 | |||||
| 43 | |||||
| 44 | |||||
| 45 | |||||
| 46 | |||||
| 47 | |||||
| 48 | |||||
| 49 |
What is the decompressed sentence?
Answer:
Comment: By the way, the sentence describes a situation where John and Jim each
took a grammar test in which they were required to indicate the number
of "had"s appropriate in a sentence. Apparently, John studied harder.
Problem 4. LZ Compressor - toy examples.
On the Lempel-Ziv compressor webpage, you can test out the effectiveness of the simple Lempel-Ziv strategy we have sketched here. Type in some sentences of standard text in the white window on this web page, and click the button "Apply LZ Compression". In the first gray window, you'll then see the result of the LZ algorithm. Because "space" is used to label the empty string (that is, "space" replaces the label zero we had before), the first few letters in the gray window will just be the letters of the text you typed, with spaces between them; as soon as a letter occurs in your white text that was already encountered before, you'll see that the encoded LZ version uses different labels. The next label is !, and then # , and so on.
In this assignment we'll ask you to try out LZ compression on a number of examples. The white window works like a very rudimentary text processor, so you can erase text, or correct it, in the standard way, by using your mouse and the "Backspace" or "Delete" key. You can also use your mouse to copy text into the white window without having to type it, if you wish, by using standard Copy and Paste techniques.
Copy and paste (or just type in) the "can can" sentence from before:
can_you_can_a_can_as_a_canner_can_can_a_can?
In the lowest gray window on this web page, you can see the length of your original sequence, the length of the encoded one, and the compression ratio, which is simply the ratio of these two lengths. We take the ratio (uncompressed length)/(compressed length), so that a ratio larger than 1 shows true compression, but a ratio smaller than 1 shows that we didn't compress at all.
The "can can" sentence has 44 characters. What is the compression ratio for this sentence?
Answer:
Now clear the input window and type in 44 identical characters, for example,
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
What is the compression ratio for this string?
Answer:
Which string compresses more and why?
Answer:
Problem 5. LZ Compressor - "real" text.
Now we will try some "real" text. Copy and paste the text of this problem set (which is roughly 20,000 characters) in the compression window. What is the compression ratio for the problem set?
Answer:
We see that on a text that is a few pages long, this naive LZ algorithm should already compress nicely.
Now let's find out how well the algorithm compresses something that is seriously long, like a long paper you wrote for another class, or a novel.
To do so, you have to cut and paste the large document of your choosing into Compressor. Instructions to do this cutting and pasting are given at the bottom of the Compressor webpage. Once you have cut and pasted your document in the top window, press the "Apply LZ Compression" button.
The compression algorithm may take some time to run, so please be patient. For example, when we used this method to compress the Bible, it took 20 minutes!
What is the compression ratio when you compress a text (of your choosing, like a paper you wrote for another class) consisting of at least 50,000 characters? Please give a one line description of the text as well.
Answer:
Finally, we will compress a book. On the Project Gutenberg webpage, hit the Select button, then browse by title or by author and find a book which is between 100K and 1000K in size of the txt file. Copy and paste the book into the Compressor. What book did you select? How many characters? What was the compression ratio?
If you have trouble with the Gutenberg site, try the online books page at UPenn. You may have to search around a bit to find a long enough book that can be viewed as a single text file.
Answer:
If you have trouble getting this to work, please send e-mail to help199@math and describe the problem you are having.
All practical implementations of the LZ algorithm use essentially the same idea as what we have seen here, combined with clever tricks that make the compression already pay off handsomely for much smaller files than the very naive version we have explored here.
We've completed the lossless text compression part of the problem set; Now let's move on to lossy image compression.
The Image Compression webpages review the simple ideas we saw in class. The type of transform explained here is called a "wavelet transform", or also "subband filtering".
At the bottom of the last page of this review, you'll see a button "Open Control Panel". Clicking this will give you access to tools with which you can explore the properties of this type of image compression.
Before starting on the real exploration, it is best to do some "warmup" exercises to become familiar with these tools.
After you click "Open Control Panel", you get a long horizontal window with two columns, and buttons that apply to "Window 1" and "Window 2". The two halves have identical functions, but they allow you to do manipulations on two separate images, so that you will be able to compare them. For the moment, let us just stick to one window.
The top left button lets you select one of three black and white images. Try out this button. When you select one image (Parrots, Window or Hat), it pops up a separate window with a information bar below it, telling you that this is the Original, and giving you the name of the image. You may have to move this window around to make sure you can see both it and the control panel. The button at bottom left gives you two choices: "Haar" or "Smooth". the Haar choice corresponds to the simple averaging and differencing scheme that was explained earlier; the Smooth choice is mathematically fancier, and you will later be asked to compare the two different choices; for the moment let us stick to "Haar".
The button with label "Which one?" gives you three choices: Original, Reconstructed or Coefficients. The button below it lets you choose a number of levels between 0 and 4. Let us set the number of levels at 1, and look at the results for the three choices in "Which one?". "Original" just gives us the original image, without any changes - this will always be the case: whatever the settings of the buttons on the bottom row, choosing "original" on the top right gives you the original image. Look at "Coefficients": then you see four little images displayed - these are the averages and differences that were described earlier; the top left gives averages in both horizontal and vertical directions, and the result is a reduced and slightly less sharp version of the original image; the other three rectangles correspond to differencing horizontally or vertically or in both directions. For these differences, which can be negative as well as positive, zero is displayed as middle gray; darker or lighter gray (with black and white as extremes) correspond to non-zero negative or positive coefficients.
If you change the number of levels to 2, then the top left rectangular image undergoes another round of averaging and differencing (try it); we can go up to level 4. If the number of levels is zero, then we are back at the original - no averaging or differencing. (Note that the information bar at the bottom of the image tells you what you are looking at : what image, what filter (Haar in our case here), number of levels.)
The choice "Reconstructed" under "Which one?" just gives the reconstruction from all those averages and differences, and it looks (of course) just like the original. This becomes more interesting when we start playing with the last remaining button, labeled "Number of rounded bits". All the coefficients are always rounded off - we don't store these numbers with arbitrary precision. The original images come with 256 gray levels, or 8 bits. When we start to compute our averages and differences, they require, in principle, at least as many (and in fact slightly more) bits. We can vary the round off that we shall apply to all the coefficients; if the Number of rounded bits is set to zero, no such rounding off takes place; we can choose the Number of rounded bits to take any value between 0 and 9. The choice 9 corresponds to the highest number of rounded bits, so expect the worst quality for the Reconstructed image with this option. In particular, when the number of levels is zero, the choice of 9 Rounded off bits corresponds to putting everything to zero - you'll see a black Reconstructed Image: everything is zero. (Try it!) Going to 8 rounded bits shows you only black and white: we have now two possible values. As the number of rounded bits decreases, more gray levels are available. When you increase the Number of Levels up from zero, even 9 rounded off bits will give you something, (because these coefficients may have more than 9 bits to start with, so that something can remain after removing 9 bits). But here too, you can observe how the quality of the Reconstructed Image improves as the Number of Rounded Bits decreases.
The information bar underneath the image has a lot of entries when you look at a Reconstructed image. It tells you not only the name of the image, the number of levels in the averaging and differencing scheme, what filter (Haar or Smooth) was used, and the number of bits rounded, but it also gives bitrates for three different compression schemes. What this means is that after you set all the parameters, you find out how much bits would be used by a true coder (using one of three schemes: Fano, Huffman, and RunLength) per pixel. Without coding, you would need 8 bits per pixel to store the image. After the lossy transform, followed by (in this case) a lossless coder, the bitrate or number of bits per pixel, is significantly lower. (Huffman coding is a scheme we discussed in class; RunLength is a scheme that is very good at compressing information in which you have long identical strings; this will be good here if we round a lot of bits, so that we have long strings of coefficients that have been rounded off to zero.) The compression ratio given is simply the ratio of 8 to the lowest of the three bit rates. (The first-order entropy is a number that gives a theoretical guess of the bitrate to which you could compress the rounded off coefficients; it is often lower than the bitrate that is actually achieved by the schemes that are tried out, except in those case where there is so much roundoff that RunLength wins - then the first-order entropy is not a good indicator.)
Play with all these buttons, until you know what is where, and you get a feeling for what you can do. Note that not all buttons affect the display, depending on what options you chose. For instance, if you choose to look at the Original Image, then the choice of Filter or Number of levels, or Number of rounded bits, won't matter. If you look at Coefficients, then you will always "see" the coefficients as they are computed, before rounding off, so the Number of rounded bits does not affect this either. For each button, the control panel indicates in color what version will be affected by this control button.
You can do exactly the same manipulations, independently, to a second image, controlled by the buttons in "Window 2". By choosing the settings in these two windows, you will now be able to carry out comparisons.
Problem 6. Wavelet Coefficients.
In the "Coefficients" display (with the Filter set to Haar and Levels set to 1), the three different "difference" rectangles correspond to a special kind of information. It is perhaps easiest to see the differences in the Window image. By comparing with the original image, you can see that the difference coefficients that are non zero come from particular regions in the image. What regions? Can you explain why the difference coefficients would be especially large there? What is the difference among the three types of difference coefficients (corresponding to the three different rectangles)?
Answer:
Problem 7. Wavelet Transforms.
First of all, let's see how useful these transforms are in the first place. Choose a noticeable but not extreme number of bits to be rounded off (4 or 5) and check the quality of the reconstructed image, after Haar filtering, depending on the number of levels - 0 levels meaning that you didn't do a transform but rounded off in order to get compression. Compare the compression ratios as well. Try it for at least 2 of the 3 images (Parrots, Hats or Window) and describe your observations. What do you conclude: Is it useful to do the transform before rounding off? How many levels of transform did you find most useful?
Answer:
Problem 8. Rounding.
Set the number of Levels at 4, and let us look closely at the reconstruction as we change the number of rounded bits. Compare with the original at all times. What are the features that deteriorate as the number of rounded bits increases? Describe, in some detail, for the three images (Parrots, Hats and Window). Is there are relationship between more rounding bits and compression?
Answer:
Problem 9. Comparison.
With Levels = 4, for each of these three images, give the number of rounded bits, and the compression ratio, for which you found the reconstructed image of comparable quality to the original:
Answer:
Parrots:
Window:
Hats:
And the number of rounded bits, and the compression ratio, for which you found the reconstructed image of unacceptably low quality?
Answer:
Parrots:
Window:
Hats:
Problem 10. Filter Comparison.
Finally, we are going to compare the Haar filter and the Smooth filter. The Smooth filter corresponds to a fancier way of computing "generalized" averages and differences that is used quite a lot in this type of image compression (it is used, for instance, by the FBI for its compression scheme for fingerprints). For the 3 different images, with Levels set to 4, look at the quality of the reconstructions after rounding off varying numbers of bits. Look at the overall quality, at the type of artifacts (changes introduced by the compression scheme), at special details (the writing on the caps and the sky in Hats, for instance, or the lines around the eyes and the blurry background or the feathers in Parrots), and the compression ratios. Give your observations. Which of the two filters do you prefer and why?
Answer:
In practice, fancier schemes than simple rounding off are used, and one finds that compression ratios of 16 to 20 can often be obtained with Reconstructed Images that are comparable in quality to the original.
Problem C1. Huffman code for Russian alphabet or image data.
Create a Huffman code for a Russian alphabet and its frequencies given in a table below.
| Russian letter | Letter's name in Russian |
Pronounced as | Transliteration | Frequency |
|---|---|---|---|---|
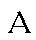 | "ah" | a in car | a | 0.062 |
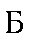 | "beh" | b in bit | b | 0.014 |
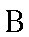 | "veh" | v in vine | v | 0.038 |
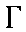 | "geh" | g in go | g | 0.013 |
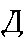 | "deh" | d in do | d | 0.025 |
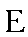 | "yeh" | ye in yet | ye or or e | 0.071 |
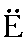 | "yo" | yo in yolk | yo | 0.001 |
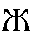 | "zheh" | s in pleasure | zh | 0.007 |
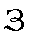 | "zeh" | z in zoo | z | 0.016 |
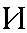 | "ee" | ee in see | i | 0.062 |
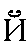 | "ee kratkoyeh" "short ee" | y in boy | i or y or j | 0.010 |
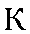 | "kah" | k in kitten | k | 0.028 |
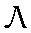 | "ehl" | l in lamp | l | 0.035 |
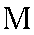 | "ehm" | m in map | m | 0.026 |
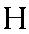 | "ehn" | n in not | n | 0.053 |
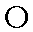 | "oh" | o in folk | o | 0.090 |
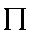 | "peh" | p in pet | p | 0.023 |
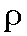 | "ehr" | r in roll | r | 0.040 |
 | "ehs" | s in see | s | 0.045 |
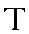 | "teh" | t in tip | t | 0.053 |
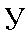 | "oo" | oo in boot | u | 0.021 |
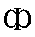 | "ehf" | f in face | f | 0.002 |
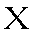 | "khah" | h in house | kh or h | 0.009 |
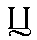 | "tseh" | ts in sits | ts | 0.004 |
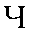 | "cheh" | ch in chip | ch | 0.012 |
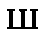 | "shah" | sh in shut | sh | 0.006 |
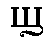 | "schyah" | sh in sheep | sch | 0.003 |
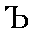 | "tvyordiy znahk" "hard sign" | separation sign | ' | 0.003 |
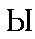 | "i" | i in ill | y | 0.016 |
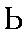 | "myagkeey znahk" "soft sign" | indicates the softness of consonants | ' | 0.011 |
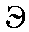 | "eh" | e in met | e | 0.003 |
 | "yoo" | u in use | yu | 0.006 |
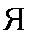 | "yah" | ya in yard | ya | 0.018 |
Problem C2. Optimal sentences for LZ Compression.
For the LZ Algorithm we explored in Problem 1, write the longest character stream which compresses to the streams of the following lengths. If it is not possible to obtain the compressed length, explain why.
6, 9, 20, 21, 22, 23, 24, 25, 45
Don't forget to explain.
Problem C3. Optimal Compression Ratios.
Using the fixed length prefix version of the LZ compression algorithm described on the Lempel-Ziv Algorithm: Coding a Text with Digits webpage, determine the compression ratio when compressing a string consisting of the same character repeated 55 times. For example, the string could be,
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Now, determine the compression ratios for strings (of a single repeated character) of length 5050, 500500, and 50005000. Show your work. You may find the following formula useful, 1+2+3+...+(n-1)+n = n*(n+1)/2.
Problem C4. Color Image Compression.
Invent the compression for Color Images. (We will be generous when deciding what is "full credit" here!)
| Start the Lab | Last modified: Wed Jul 30 17:03:21 EDT 2003 |